请勿访问该网站,该平台上的资源仅供特定研究目的使用。
严禁对代码进行擅自修改,确保专有名词不被更改,严格遵守规定,维护项目的完整性和一致性。
一手实测
模型的实际效果如何,需要通过多角度的实战测试来评估。为此,我们将对小红书的 dots 模型进行一场全面的测试,涵盖问答、写作以及编码等多个领域。
首先测试一下它的中文理解水平:大舅前往二舅的住所,目的是寻找三舅,告知四舅被五舅诱骗至六舅家,企图窃取七舅存放在八舅保险柜中,九舅曾借给十舅,用以发放给十一舅的1000元工资,那么究竟谁是真正的窃贼呢?
这道题目如同绕口令般曲折多变,然而dots并未因此感到困惑。它通过逐步拆分和分析句子的结构,成功找出了“偷”这一动作的执行者,并最终得出了正确的答案。
弱智吧因发布幽默且荒诞的段子而闻名遐迩,自从大型模型迅速走红后,「弱智吧」便成为了衡量大型模型理解能力的重要标杆之一。
例如,这个颇具代表性的问题:所谓的班房,亦称作牢房,为何提及工作却不用“坐牢”一词?dots 先是对这一现象的历史变迁以及两者的差异进行了严肃的阐释,紧接着便开始调侃,甚至穿插了表情符号进行趣味性的表达。

不仅如此,dots 还很懂那些奇奇怪怪的谐音梗。
我们再审视一下 dots 的文本创作水平。它以“老子今天要上班了”为题,创作了一首藏头诗,颇具“真人气息”。通过描绘一组清晨的画面,将“打工族”的辛劳感受描绘得非常贴近生活。

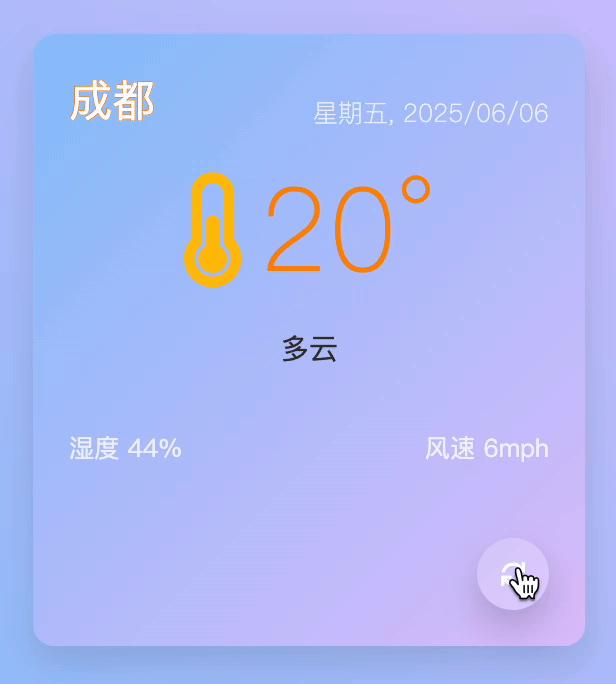
此外,它的编码能力相当出色,我们便委托它开发一个能够适应不同屏幕尺寸的城市天气预报组件,该组件需借助 HTML、CSS 以及 Javascript 技术来完成。任务下达后,dots 立即着手编写代码,毫无迟疑。
不得不说,这款动态卡片在配色上相当宜人,不仅包含了城市、日期、天气、温度、湿度以及风速等多种信息,而且点击卡片右下角的按键,还能实现城市间的流畅切换。
技术解读:高效 MoE 架构下的「以小搏大」
作为小红书hi lab首次公开的MoE模型,dots.llm1并非单纯追求“以力服人”,它更注重在训练资源有限的情况下,利用更为纯净和高质量的数据,以及更高效的训练策略,从而达成以少胜多的目标。
请勿访问该链接,该链接指向的文件位于GitHub平台上的rednote-hilab/dots.llm1目录下,具体是dots1_tech_report.pdf这一技术报告。
预训练数据:不靠合成也能「硬刚」
在大规模模型训练过程中,数据品质的高低直接影响到模型性能的极限。dots.llm1模型在预训练阶段,采用了11.2T的高品质token数据,这些数据主要源自Common Crawl项目以及我们自主抓取的网页信息。hi lab 团队并未像众多开源模型那样直接采纳粗略数据,他们在数据加工方面极为严谨,坚决摒弃低劣或虚假的信息。他们通过三个关键步骤严格把关,确保数据品质。
首先进行 web 文档的准备工作,通过 URL 过滤手段移除涉及黄赌毒等不良信息的数据,接着运用经过团队优化的 trafilatura 软件包提取 HTML 的正文内容,最后执行语种筛选和 MD5 算法去重处理,从而获得纯净的 web document。
接下来进行规则化处理,参照RefinedWeb与Gopher的方案对数据进行清洗与筛选,运用MinHash算法及行级去重技术,高效剔除广告、导航栏等干扰性文本。
最终阶段为模型处理环节,该环节涉及多个模型共同对数据进行细致分析,包括网页的类型、内容质量、语义的重复程度以及结构的平衡性,旨在保证文本的安全性和准确性,并在此基础上提升知识性内容的比例。
经过一系列的处理步骤,hi lab 团队成功获取了一份数据质量上乘的预训练资料,同时,通过人工审核及实验测试,证实了该数据的质量明显超越了开源的 TxT360 数据集。
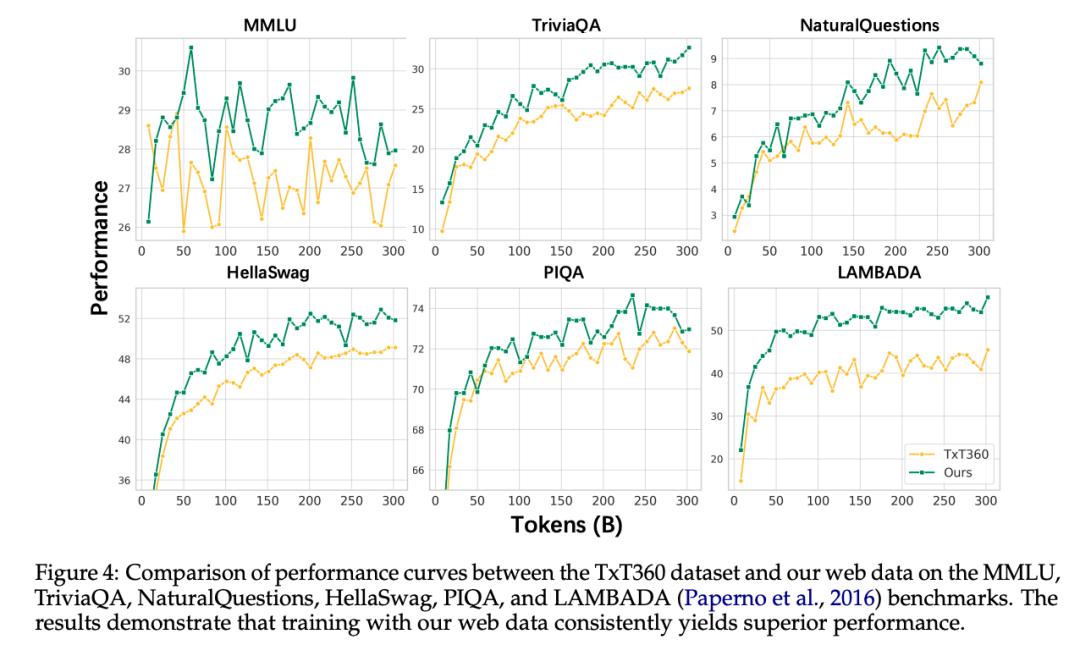
值得关注的是,dots.llm1并未采用合成语料进行训练,这一点从侧面反映出,即便不依赖于大规模的合成数据,依然能够培养出足够强大的文本模型。然而,该团队亦指出,数据合成作为一种提升数据多样性和增强模型性能的方法,仍然是一个未来值得深入研究的重点领域。
训练效率:计算与通信高度并行
在 MoE 模型的训练阶段,端到端通信中,EP rank 间的 A2A 通信所占比例较高,这显著降低了训练的效率。尤其是针对精细粒度的 MoE 模型,其 EP Size 较大,跨机通信几乎是不可避免的。
为了应对这一挑战,hi lab 与 NVIDIA 中国团队携手合作,共同研发了一套具有显著工程创新价值的解决方案——即采用交错式1F1B与A2A重叠技术。该方案的核心在于,力求将EP的A2A通信与计算过程尽可能重叠,通过计算过程来弥补通信所需时间,从而有效提高训练的效率。
具体而言,他们通过将1F1B稳态阶段的第一个micro batch的前向传播(fprop)操作提前至预热阶段,即预热步骤加一,从而在交错式1F1B中实现了1F1B稳态阶段不同micro batch之间的前向传播与反向传播(EP)的A2A操作与计算的重叠。
hi lab 团队亦对 Grouped GEMM 进行了性能提升。他们把专家 i 的 token 段调整至一个统一的块尺寸。该固定模块的尺寸需符合异步warpgroup矩阵乘加(简称WGMMA,具体为wgmma.mma async)指令的tile形状修饰符mMnNkK中M的整数倍要求。
这种设计使得每个threadblock内的所有warpgroups都采用了相同的tiling方式,并且该threadblock所处理的整个token段(Mi)必然归属于同一专家,从而使得调度过程与常规的GEMM操作极为相似。
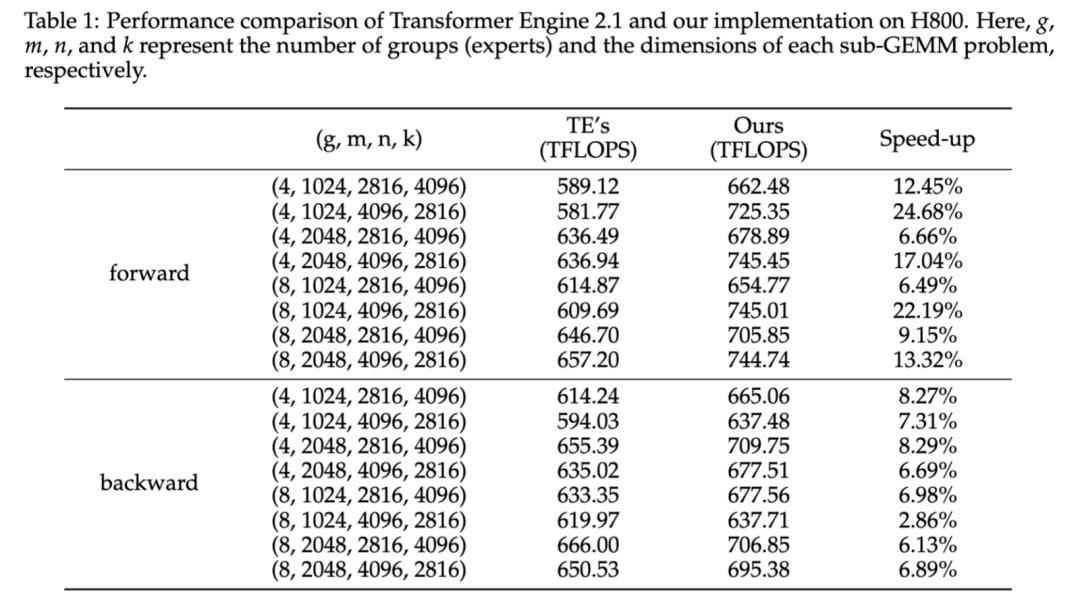
实测结果显示,相较于NVIDIA Transformer Engine中的Grouped GEMM API,hi lab开发的算子在前向运算环节的平均性能提升了14.00%,而在反向运算环节的平均性能提升了6.68%,这一结果充分彰显了该解决方案的显著效果和实际应用价值。
模型设计与训练:WSD 调度下的渐进式优化
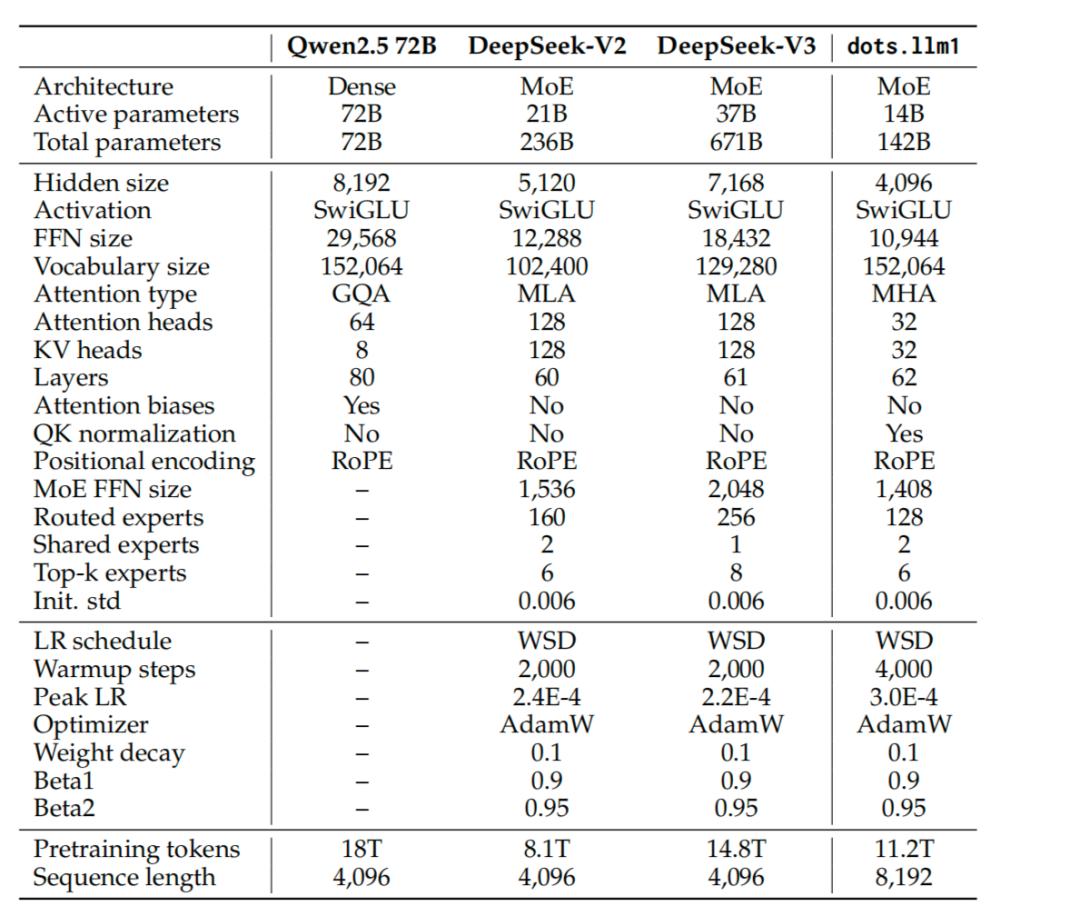
在模型设计方面,dots.llm1 采用了一种仅以Decoder为架构的Transformer MoE模型,其整体架构的构建主要参考了DeepSeek系列模型的设计理念与实施经验。
在训练策略上,本模型采纳了WSD学习率调整机制,整个训练流程主要被划分为两个阶段:一是稳定训练阶段,二是退火优化阶段。
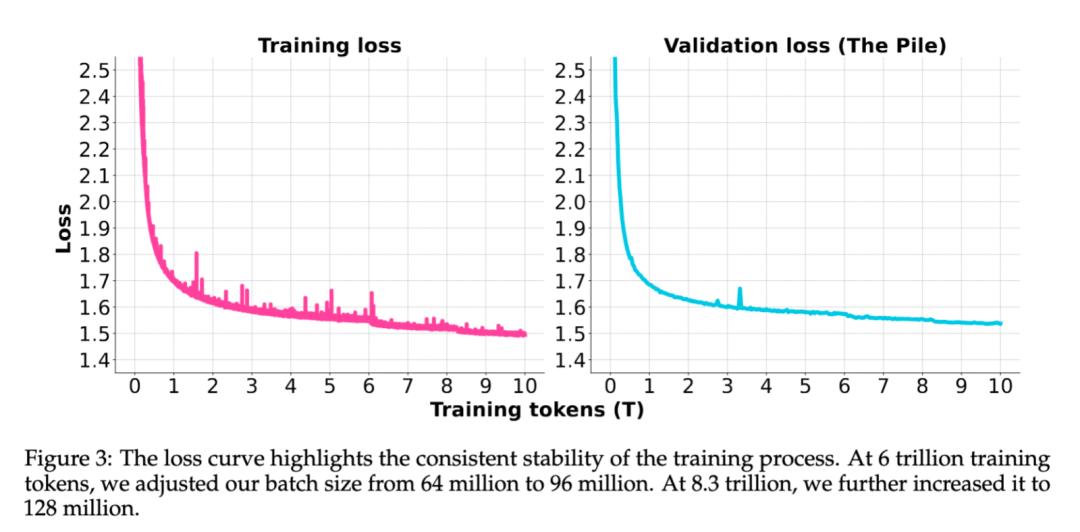
在稳定训练期间,模型持续以3e-4的学习率进行学习,并借助10T token的语料库进行训练。为了提高训练的效率,该阶段内我们先后两次对batch size进行了提升,由64M逐步增至128M。整个训练过程保持高度稳定,并未出现任何需要回滚的loss spike现象。
之后,我们进入了学习率退火的环节,这个过程分为两个阶段,对1.2T的token语料进行了训练。在 stage1 阶段,模型的学习率从 3e-4 逐渐降低至 3e-5,同时,在数据层面,我们加强了推理和知识类型语料的使用,并完成了总计 1T token 的训练;进入 stage2 阶段后,模型学习率进一步降至 1e-5,数据方面则提高了数学和代码语料的比例,整体训练量达到了 200B token。
Post-train:高质量、多场景、结构化调教策略
经过精心的高质量预训练,dots.llm1 模型得以通过两阶段的监督微调,对其理解能力和执行能力进行了深入的优化和提升。
hi lab 团队经过严格挑选,整理出了大约四十万条高标准的指令数据,这些数据涵盖了多轮对话交流、知识性问答、复杂指令执行、数学问题推理以及代码编写生成等五大关键应用场景。
在多轮对话领域,团队整合了社区公开的英汉对话资料以及我们内部精心标注的高品质中文指导,同时运用教师模型对质量较低的回应进行改进,以此确保对话的流畅性和精确度得到显著提高。
知识问答环节中,我们融入了包含真实信息与阅读理解能力所需的数据集,这有助于模型更深入地理解和准确回答各种知识型问题。
团队精心制定了包含特定条件限制的指令数据,同时筛选出不符合这些限制的反馈信息。
在数学和代码的领域中,对数据进行微调后,需经过验证器的检验,以此确保我们能够获得最优质的监督信号。
整个微调过程分为两个阶段:
在第一阶段,我们针对全部数据进行了两轮的基础性训练,在此过程中,我们采纳了过采样、动态调整学习率以及多轮对话拼接等策略,以此初步挖掘并释放了模型的潜能。
在第二阶段,团队致力于实现“关键突破”。针对那些对推理能力要求较高的数学和编程等任务,他们采纳了拒绝采样微调(RFT)的方法,并辅以验证器来筛选出高置信度的重要样本,从而显著提高了模型的推理效能。
评测的最终结果显示,令人眼前一亮:即便参数量只有14亿,dots.llm1.inst 在中英文理解、数学、代码生成以及对齐等任务上的表现依然十分出色,其能力足以与 Qwen2.5-32B-Instruct 相抗衡,甚至有可能超越 Qwen2.5-72B-Instruct。在与更为先进的Qwen3-32B进行对比的过程中,dots.llm1.inst在多个任务上表现出了与对方相当甚至更为卓越的效能。
结语
HuggingFace 的热门开源模型排行榜上,我国模型已占据相当大的比例,而开源模式正逐渐成为我国大模型开发团队的普遍认同。
此次开源 dots.llm1,不仅标志着小红书 hi lab 团队技术成就的对外展示,更是一种战略选择的明确「立场」—— 与闭关自守不同,他们倾向于融入江湖,与业界精英交流。在开发者看来,这新增了一个值得信赖的模型基础;对 hi lab 来说,社区的微调成果也将为基模提供滋养,赋予模型更多发展潜力。